
Can Social Bookmarking |
Search is probably the most important application on the web. Arguably, both Google and Yahoo! are currently sustained by selling sponsored search ads next to search results.
The history of web search has been a series of big jumps in search quality followed by relative lulls. For example, the introduction of link structure to determine authority (e.g., PageRank and HITS) around 1998 was one such big improvement.
This leads to the big question: what will be the next big thing that substantially improves search quality?
One of the big contenders for this "next big thing" is social search: the idea of adding user annotations or other metadata to the process. Of course, arguably "search" has been "social" ever since people began incorporating anchortext into search engines, or ever since users started contributing the first web pages.
However, usually what is meant by social search is something like incorporating user-generated tags or ratings into an index or ranking function.
Meanwhile, social bookmarking sites like del.icio.us and StumbleUpon have been growing rapidly. Both now have millions of users.
As a result, in the paper below, we ask the question: "Can Social Bookmarking Improve Web Search?". By extension, we also ask, if so, in what ways, and if not, why not?
This page attempts to give an informal introduction and description for the results that we recently presented at the Web Search and Data Mining conference.
So what's in the paper?
In the paper, we present eleven main results about the social bookmarking system del.icio.us. These results form the basis of any search functionality that might be built on top of social bookmarking.
The data gathering for our results is fairly involved, and is discussed in the paper. However, the summary is that our results are based on:
- Many months of crawling del.icio.us,
- A month of crawling all pages posted by del.icio.us users (and forward and backlinks from those pages) within two hours of being posted,
- Philipp Keller's del.icio.us posting dataset, and
- The infamous ("infamous" link mildly NSFW) AOL query log dataset.
We divide the results into positive (+) and negative (-) for the impact social bookmarking might have on web search. We further subdivide the results into those that are about the URLs being bookmarked (URLs), and the tags that people apply (tags).
Super Executive Summary
- Social bookmarking URLs are full of new and fresh information (Results 1 and 2).
- Tags on URLs are often redundant given title, domain, and page text (Results 10 and 11).
- Social bookmarking is probably still a bit small to have a big impact on web search (Results 8 and 9).
Results
Result 1: Recently Modified (+/URLs)
Pages posted to del.icio.us are often recently modified. The histogram below (click for larger version) shows how recently a page just posted to del.icio.us was modified.

For example, if a page (say, Slashdot) was just posted by a user (say, "Bob") and when it was posted, that page was changed one day ago, it would slightly increase the height of the bar above one day. Time is in log-scale.
What this graph shows is that the bulk of posts to del.icio.us are modified either about a day ago, or about ten days ago, at the time when they are posted.
Of course, information like this is useless without context. So the question is, what kinds of pages do users usually see, and how recently are those pages generally modified?
We compared to two things:
- The Open Directory Project (ODP), a large directory similar to Yahoo! Directory.
- Yahoo! Search results (either the top 1, top 10, or top 100 results for queries).
For ODP, we randomly sampled URLs from the data dump. We then searched for those URLs with the Yahoo! Search API, and recorded the ModificationDate attribute (see here and here for ModificationDate attribute information). Because HTTP/1.1's Last-Modified header turns out to be infrequently used and often incorrect, it's more sensible to use a search engine's information on recency. We determine the recency for del.icio.us URLs in the same way.
For Yahoo! Search results, we randomly sampled queries from the AOL query log dataset. We then submitted the queries to the Yahoo! Search API. Lastly, we looked at the ModificationDate attribute for either the top 1, top 10, or top 100 results returned for each query.
The end result of these two processes is a general picture of recency of web directories and search results that we can compare to del.icio.us (click for larger version):
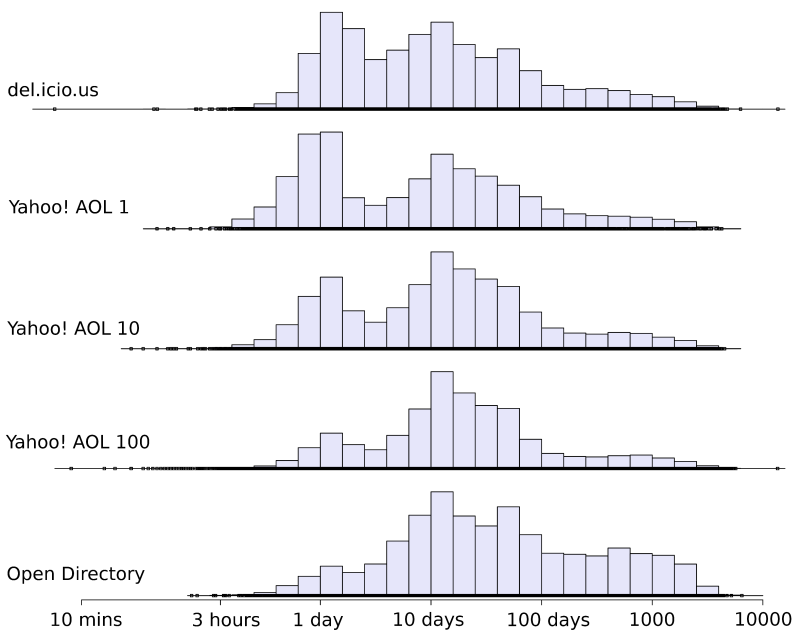
Looking at these histograms side-by-side, three things are apparent.
- Search engines like to return more recently modified pages. Furthermore, the first result returned for a query is generally more recently modified than the top 10 results which in turn are generally more recently modified than the top 100 results.
- The distribution of URLs posted to del.icio.us is very similar to the distribution of URLs that search engines like to return.
- Both del.icio.us and search results tend to have much more recently modified URLs than ODP.
The broad conclusion is: del.icio.us users post interesting pages that are actively updated or have been recently created. What this means is that search engines could probably change their crawl scheduling (see here) to produce better, more up-to-date results.
Result 2: New and Unindexed Pages (+/URLs)
At any given time, a search engine can only crawl and index a portion of the web as a whole. The challenge is to determine which parts are worth crawling (as they are created) and to crawl those parts as quickly as possible. Approximately 25% of URLs posted to del.icio.us by users are new, unindexed pages which will later be indexed.
In order to get this result, we searched for URLs using the Yahoo! Search API as they were posted. In 37.5% of cases, URLs were missing when we searched for them. Over the next six months, we continuously searched for a sample of the missing URLs.
We assumed that if a URL was not returned by a search, it was currently unindexed. If at a later point the URL was returned by a search, it had been indexed, and was worth indexing. On the other hand, if a URL was never returned by a search, we don't know anything. It could be a useless URL, or it could be a URL which still was not found by crawlers six months after posting.
Our results were:
| URLs Found Initially | 57.5% |
| URLs Indexed Within Four Weeks | 12.75% |
| URLs Indexed After Four Weeks (Within 6 Months) | 12.75% |
| Never Indexed | 17% |
The sum of the URLs indexed within four weeks and within 6 months is about 25%.
The broad conclusion is: del.icio.us can serve as a (small) data source for new web pages and to help crawl ordering.
Result 3: Search Result and URL Overlap (+/URLs)
One big question is how the URLs that people choose to post about relate to the sorts of URLs that are returned as search results.
For example, if a search engine has tagging or bookmark information for all of the top 10 results for a query, it might be able to change the ordering of those results based on the information. However, if most tagged or bookmarked URLs are less popular search results, then social bookmarking is less useful for search.
In order to answer this question, we:
- Sampled queries from the AOL query log dataset.
- Submitted those queries using the Yahoo! Search API.
- Looked in the top 10 and top 100 results for URLs that were present in del.icio.us.
What we found was that overlap between del.icio.us and search results was much higher than you might expect by (uniformly distributed) chance.
Based on the size of del.icio.us, one might expect one thousandth of the
search results to also have been posted to del.icio.us.
However, we found much greater frequency of URLs posted to del.icio.us in
search results:
| Top 10 Search Results in del.icio.us: | 19% |
| Top 100 Search Results in del.icio.us: | 9% |
The broad conclusion is: del.icio.us URLs are disproportionately common in search results compared to their coverage. This makes sense, especially in light of recent news that Yahoo! is integrating del.icio.us into their search results user interface.
Result 4: User Concentration (+/URLs)
Previous work has shown that social websites can become highly dependent on a small group of users. For example, on the social news site Digg the top 100 users control 56% of the content.
A reasonable question is whether del.icio.us is similarly concentrated. If a significant number of users left del.icio.us, would it disappear? Would the content change substantially?
For a one month period, we looked at the proportion of posts contributed by the top n users (click for larger version):

For example, the top 100,000 users contribute a little over 80% of the content. The graph shows that there are a number of users who are highly active, core users. However, in order to cover over 50% of the content posted, one needs to include over 30,000 users (a far cry from Digg's 100).
The broad conclusion is: del.icio.us is not highly reliant on a relatively small group of users (e.g., <30,000 users).
Result 5: High Proportion of New URLs (+/URLs)
Users of social bookmarking sites are probably acting largely out of self interest rather than in concert. This means that their actions are largely uncoordinated.
One danger of this is that users could post the same URLs over and over again. For example, the system could have huge amounts of information about Slashdot or CNN and none about smaller sites.
The figure below (click for larger version) shows the distribution of the number of times a URL just posted is previously in del.icio.us:

For example, about 20% of posts refer to URLs which are posted more than 50 times.
The interesting result here is that 30-40% of posts (once we account for filtering, discussed in the paper) are the first post of a URL to del.icio.us. This suggests both that del.icio.us has a large amount of information for popular URLs, and a broad collection of less popular URLs.
In order to avoid counting many URLs from the same site, we also looked at new domains. However, our numbers there are approximate. We found that approximately one in eight posts referred to URLs whose domains did not appear to have been in del.icio.us previously.
Our broad conclusion was that del.icio.us has relatively little redundancy in page information for perhaps 50% of URLs and high redundancy for perhaps 20%.
Result 6: Query Terms and Tags Overlap (+/Tags)
A search engine needs to do two things to return a list of results:
- Find pages relevant to a query.
- Rank them according to some criterion (authority, prestige, relevance).
Some recent work has looked at this question. For example, Optimizing Web Search Using Social Annotations suggests using an algorithm similar to SimRank to do so.
We looked at the overlap between the queries in the AOL query log dataset and tags annotating URLs in del.icio.us.
We found that there doesn't seem to be much correlation between the popularity of a tag and the popularity of a query term. However, there is relatively high overlap between popular query terms and popular tags.
The scatter plot below shows the popularity of a query term in the AOL query log dataset versus the popularity in del.icio.us (click for larger version):
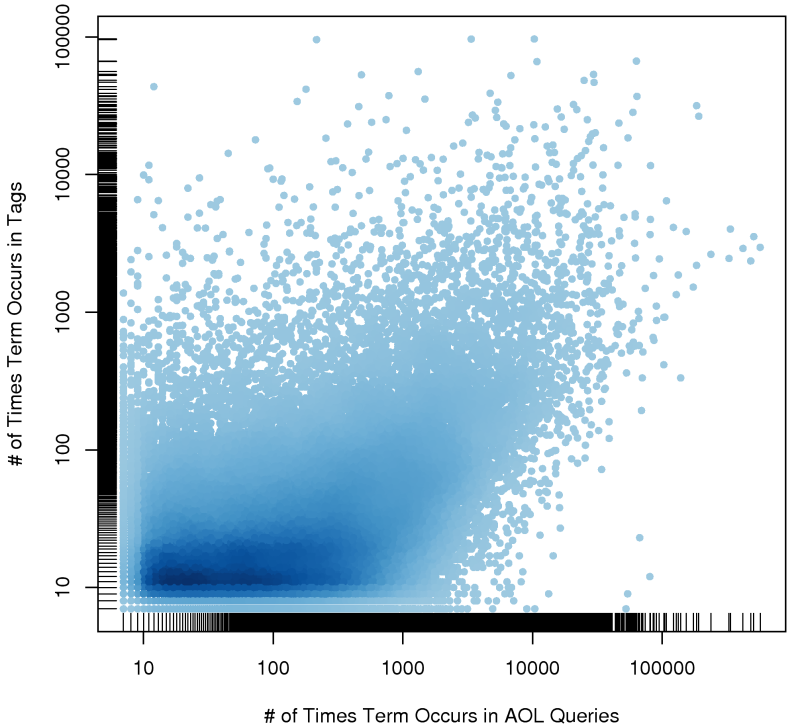
For example, a term that occurs tens of thousands of times in queries but only occurs a few times as a tag would be represented by a dot in the lower right corner.
It might be possible that if you eliminated rare queries and rare tags that there might be a little bit of correlation. However, in general, the most popular queries seem to be heavily navigational, in contrast to the (arguably) categorical nature of tags.
For example, "google" is one of the most popular queries, while "design" and "web" are very popular tags.
The broad conclusion is: del.icio.us may be able to help with queries where tags overlap with query terms, and there is a reasonably high overlap (if not correlation) between tags and query terms.
Result 7: Tags are Relevant and Objective (+/Tags)
One early complaint that many people have about tags is that users can just add whatever they want. If users can add whatever they want, they'll probably add a bunch of junk. By junk, we might mean spam, or we might mean how the user feels about the page, or just something that is irrelevant.
Not being able to determine whether a tag is junk in an automated way, we did a user study. We gave each user a sampling of postings, with some postings overlapping with other users to determine whether the users agreed with each other. There were ten users and between 100 and 150 posts per user.
We asked users whether each tag was subjective, irrelevant, and a few other questions. For example, "funny" is subjective. The tag "c++" might be irrelevant for a page about sports. We also asked if the users found any spam, and we did not find any (possibly due to filtering).
| % of Tags Users Found Irrelevant: | 7% |
| % of Tags Users Found Subjective: | <5% |
Our broad conclusion was that tags are on the whole accurate. This suggests that tags are good data, even if they may be redundant given other information that search engines might have (see Results 10 and 11).
Result 8: ≈120k URLs Posted Per Day (-/URLs)
How fast are users adding bookmarks to del.icio.us? This is a relevant question both because it determines how big a phenomenon del.icio.us is, and how fast it is growing.
In around June of 2007, the answer was about 120,000 public posts per day. This number was fairly constant for the year.
We gathered our own data to determine this, though we also compared to some data gathered by Philipp Keller.
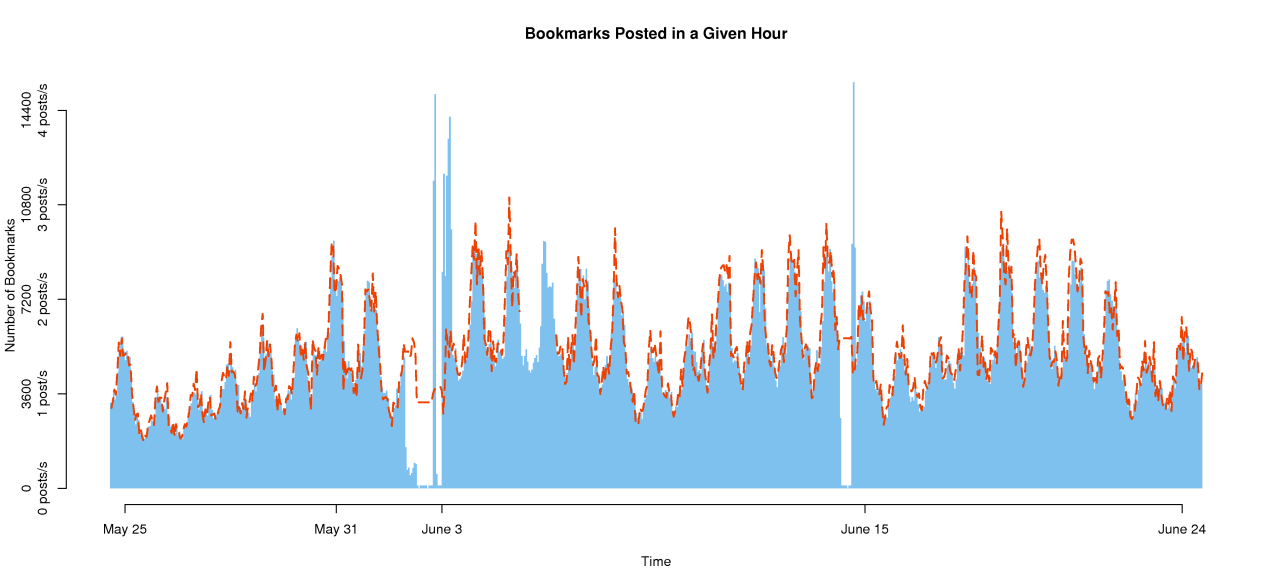
The result for our month long dataset from May to June is shown here. (It's too big to fit inline in this text, so click the "here" link and scroll along.)
{kind=link}
The solid blue lines show our data, while the red-dashed lines show Philipp Keller's data for the same time period.
The posts per day go up during mid-day and go down at night. They also drop on weekends. The two large spikes are outages when del.icio.us went down.
While the posts per day appears quite variable in this graph, it actually ends up being quite stable when looking at months of data.
Of course, without any contrast, the 120,000 posts per day is not particularly meaningful. A reasonable contrast is blogs, which are also user-created and also have new and recent URLs and other information.
Sifry's State of the Live Web for April 2007 suggests that there are over 1.5 million blog posts per day. This suggests that social bookmarking may still be about an order of magnitude smaller in posts/day than blogging.
Our broad conclusion is that the number of posts per day is relatively small, perhaps one tenth of the blogosophere.
Result 9: Size of del.icio.us (-/URLs)
The web is a huge place. No one agrees on how huge, and search engines have stopped counting.
The question depends a lot on how one counts dynamic content. For example, is Digg one page? Hundreds of pages? Millions of pages?
A reasonable ballpark estimate of the number of "pages" that search engines are currently indexing is perhaps tens of billions of pages.
We do a bunch of math to approximate the current size of del.icio.us, based on historical assumptions and based on Philipp Keller's data. In the end, we conclude that there were roughly 115 million public posts, coinciding with about 30-50 million unique URLs in del.icio.us as of June 2007.
Tens of millions of unique URLs is certainly a lot! However, it would seem to be a relatively small portion of a web that has grown to tens of billions of pages and is still exploding.
In the context of such a young phenomenon as social bookmarking, perhaps a better question than "How big is it?" is "How fast is it growing?". However, this question is more uncertain.
We analyzed Philipp Keller's data, which tells two different stories.
From August 2005 to August 2006, the story is rapid, linear growth (click for larger version):
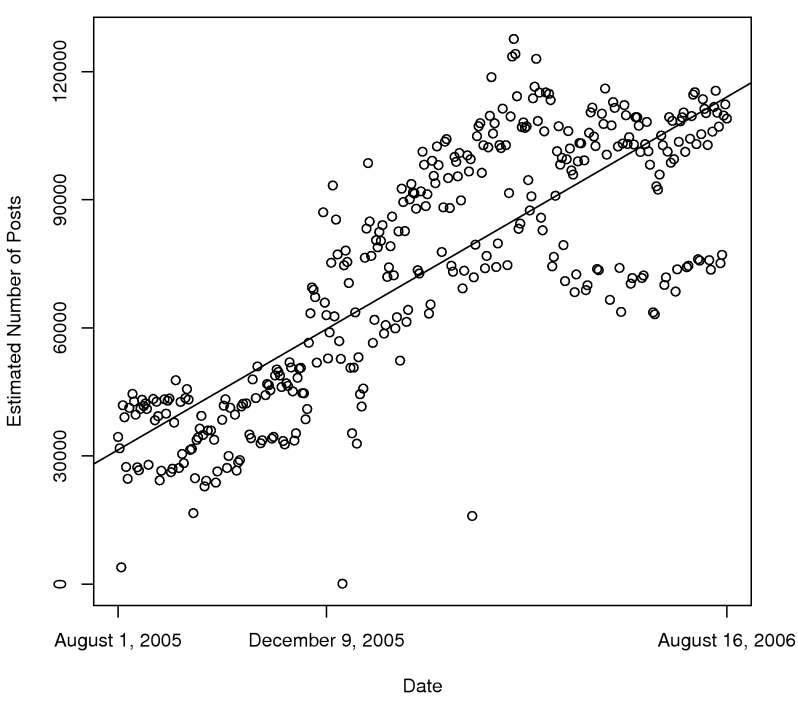
In the space of a year, the number of posts per day triples, from 30,000 posts per day to 90,000 posts per day. Much of this expansion seems to be due to Yahoo!, which purchased del.icio.us on December 9th (shown on the graph).
From November 2006 to July 2007, the story is relative stability (click for larger version):
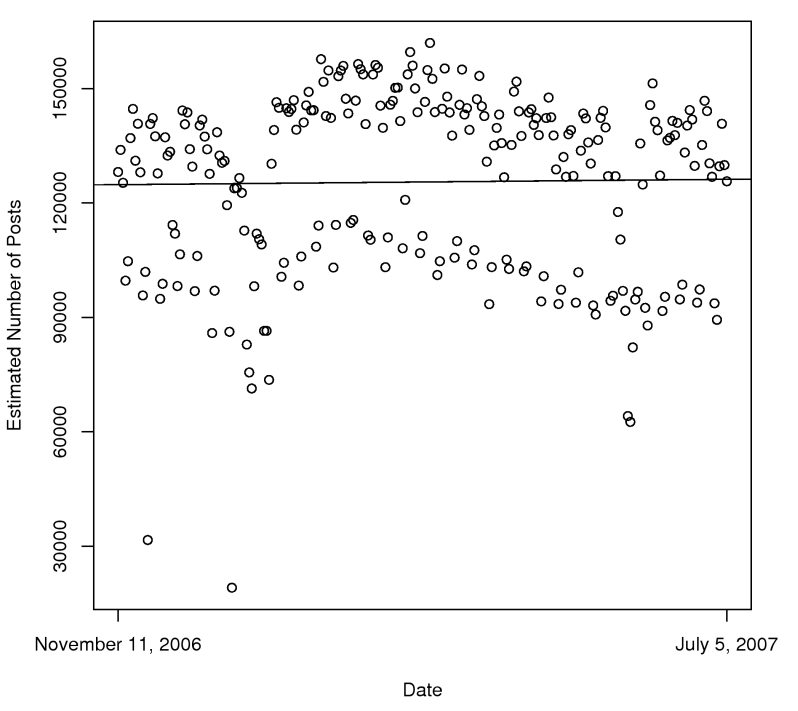
Every day, around 120,000 posts are being posted. When we combine the two time periods, we end up with two totally different trends (click for larger version):

This suggests that the growth of social bookmarking probably depends much more on marketing and other external factors than on organic growth. In other words, we are not really comfortable predicting where social bookmarking will be months from now, or years from now.
Our broad conclusion is that the number of total URLs is relatively small; it is a small portion (perhaps one thousandth) of the web as a whole. Furthermore, the future growth of social bookmarking is difficult to predict given the information we have now.
Result 10: Tags Commonly Occur in Page Text (-/Tags)
Since tags became prevalent several years ago, people have wondered about what they represent. In particular, are tags only useful for sites like Flickr and YouTube where there is no other text available? Or are tags useful even when substantial additional text is available, which is often the case on the web?
With our crawl data, we were finally able to compare the tags to the text of the pages they annotate.
Perhaps the most striking result is that in about one sixth of cases, a tag annotating a page will occur in the title of that page.
For example, the del.icio.us page for CNN shows that the two most popular tags for CNN are "news" (11473 times) and "cnn" (2499 times) two tags which are present in the title ("CNN.com - Breaking News, U.S., World, Weather, Entertainment & Video News").
Next most interesting is that tags occur in the page text of about half the pages they annotate. For example, a page tagged "cows" will have the word "cows" somewhere in it.
Finally, if we look at the page and all of its surrounding pages (pages that link to that page and pages that are linked from that page), a tag will be in all of that text 80% of the time.
In summary:
| Tag in Title | 16% |
| Tag in Page Text | 50% |
| Tag in Page Text + Surrounding Text | 80% |
What this suggests is that in a substantial number of cases, tags are not really significantly different information than the page text already being indexed by search engines.
Furthermore, search engines already heavily emphasize titles when returning results.
However, tags may have the function of emphasizing some aspect of the text which might not have been emphasized by the page itself. So in that respect they may be useful.
For example, a page about "oil prices increasing" might have a small note about "inflation" at the bottom, but if a user tags that page with "inflation", it might imply that "inflation" is a more important concept for the page than is stated in the text.
Our broad conclusion is that a substantial proportion of tags are obvious in context, and many tagged pages would be discovered by a search engine. In terms of lessons for tagging systems in general, this may mean that while tagging for media sharing sites like Flickr and YouTube works well, tagging may be less informative for systems which already have full text.
Result 11: Domains and Tags are Correlated (-/Tags)
On the web, sites tend to be organized into domains. This in turn means that domains tend to be topical.
Furthermore, when a site outgrows a single domain, it tends to create a number of subdomains. For example, Slashdot has a number of subdomains pertaining to different topics, like games and development.
This means that domains already contain some of the categorical or topical information that tags are supposed to be adding.
For instance, in one of our datasets, more than 10% of the URLs tagged "java"
are at one of five java-related domains:
| Host | Host % of Tag | Tag % of Host |
| java.sun.com | 5% | 87.7% |
| onjava.com | 3.2% | 81.5% |
| javaworld.com | 3.1% | 82% |
| theserverside.com | 1.6% | 67.9% |
| today.java.net | 1.3% | 88.7% |
In this table, java.sun.com represents about 5% of URLs tagged with "java", and 87.7% of the URLs posted to del.icio.us that are at java.sun.com in this dataset are tagged "java".
In the paper, we go into some depth predicting tags based on domains in one of our datasets.
We also asked our users in our user study whether tags applied only to the URL involved or whether they applied to the entire domain. Our users said that about one in five tags applied not just to the URL in question, but to the domain as a whole.
Both of these statements, both in terms of prediction and in terms of our user study suggest that a well financed search engine could pay "librarians" to tag entire domains rather than single URLs. Our broad conclusion was that paying such librarians would be more efficient, and might obviate the need for about 20% of the tags on URLs bookmarked.
Conclusion
Overall, the conclusion seems to be that it might be a little bit early (due to size issues, Results 8 and 9) for social bookmarking to have a big impact on web search.
However, there are some aspects of social bookmarking that mean that it could be really useful for web search, like the recency of the pages posted (Results 1 and 2) and the overlap of tags and bookmarks with queries and search results (Results 3 and 6).
On the other hand, the tags chosen by users seem to have considerable redundancy when compared to the text and domains of pages they annotate (Results 10 and 11).
Presentation (February 12th, 2008)

Can Social Bookmarks Improve Web Search?
Conference on Web Search and Data Mining (WSDM2008)
Paul Heymann
Papers
| Title: | Can Social Bookmarking Improve Web Search? |
| Authors: | Paul Heymann, Georgia Koutrika, and Hector Garcia-Molina |
| Type: | Conference Paper |
| Keywords: | Social Bookmarking, Collaborative Tagging, Web Search |
| Accessible: |
(conference paper pdf)
(video)
(slides pdf)
(dbpubs info) (doi) (tech report pdf) |
| Description: | This paper was presented at the First ACM International Conference on Web Search and Data Mining (WSDM'08). The main contribution is eleven experiments evaluating different aspects of social bookmarking and their impact on web search. |